
DiVoMiner®是一站式在线文本数据挖掘与分析平台,结合传统方法和创新执行的流程,为研究者解决量化内容分析法的工具。在线完成对文本内容的分类、编码、语义判断及形成可量化数据的全部流程,内置多个文本大数据挖掘算法模型,提供灵活而强大的研究执行及团队协作管理功能,是市场上唯一兼具实用性和学术性要求的文本内容研究工具。
DiVoMiner®基于云计算、大数据技术架构,以SaaS订购账号的模式服务,用户无需安装软件在本机,通过浏览器就可登录使用,可利用线上、或是自行上传的定量与定性数据进行内容编码与统计分析。
DiVoMiner® 适合任何领域的文本分析需要。无论是新闻报道、社交媒体发文、文学作品、历史档案访谈、文字记录、学术文献、政策文本、发言稿, 图片、视频、还是结构化问卷数据、统计数据,都可以在平台上做挖掘与分析,定量与定性分析并存。
原来数月、跨年度的研究项目,数据处理的时间大为缩短,让80%时间用在研究设计及分析上,20%执行劳务性工作。 研究者即使不懂编程,也能进行文本内容分析,产出高质量的论文,达到“数据进,价值出”(data in, value out)的目标。
目前,已经有很多研究者在平台的协助下写作并发表了多篇核心期刊、C刊论文乃至SSCI期刊论文。更有众多机构用户,订购平台作为研究工具和教学工具。即使不会编程,也可以使用DiVoMiner®平台学习、进行文本内容分析,最终产出高质量的论文。
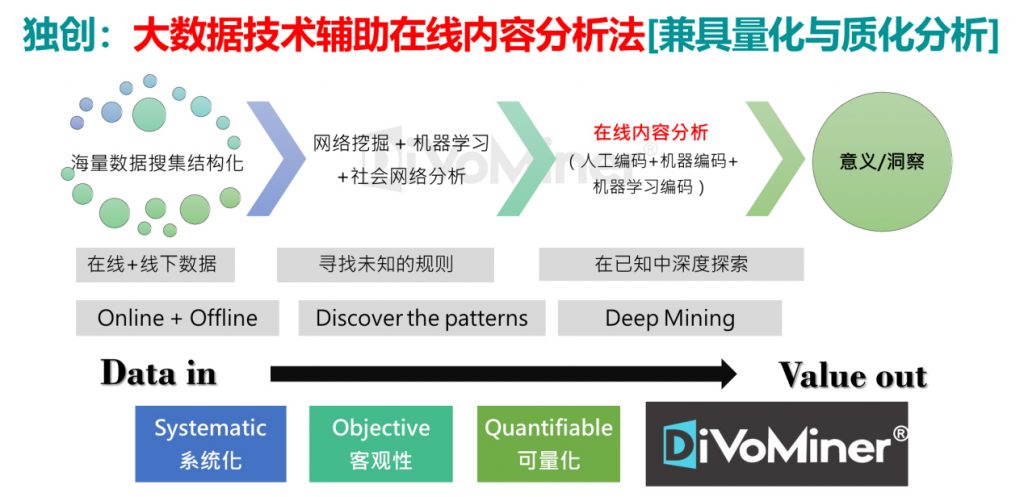
DiVoMiner®将研究方法中强调的系统化、客观性和可量化的特点贯穿始终。落实到操作流程中,可区分为准备阶段、探索、在线内容分析(编码及质量控制)和结果呈现四大部分。
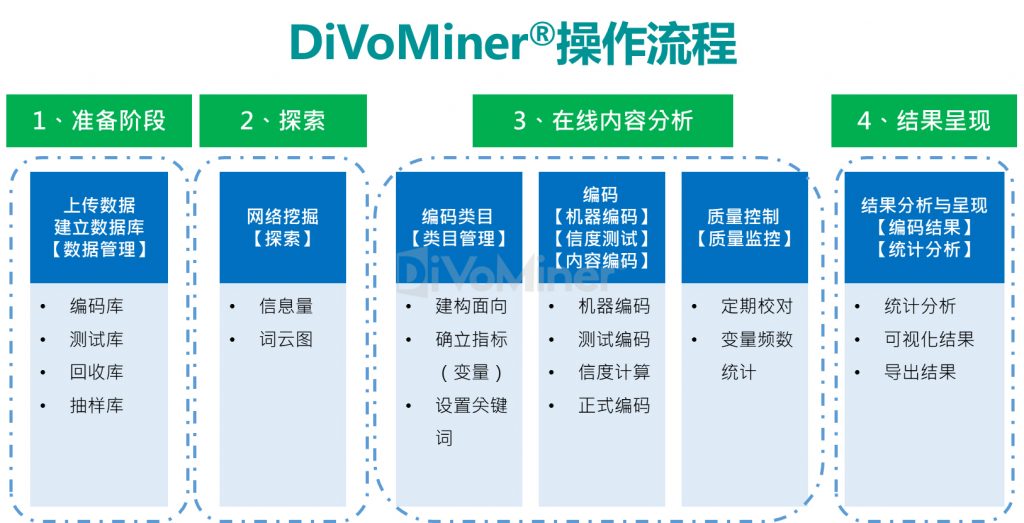
- 1. 准备阶段:
确定不同类型的数据来源,分别建立数据子库,例如,历史文献数据与社交媒体数据格式有所不同;不同的社交媒体数据类型有所不同;将格式不同的数据类型分门别类上传至对应的数据子库,完成建库过程。
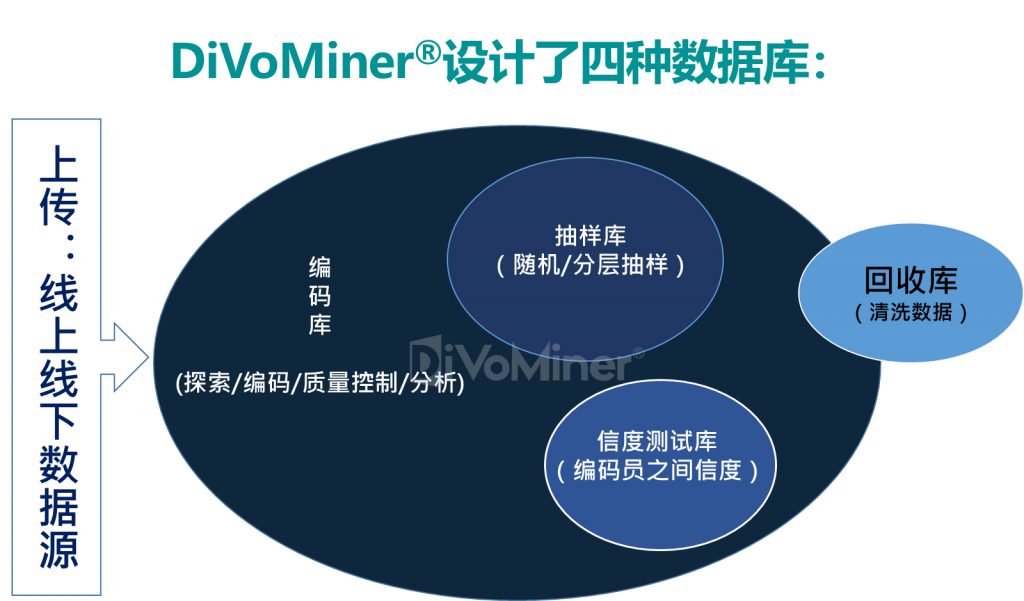
DiVoMiner®针对数据库的不同功能需求设计了四种类型数据库。用户上传数据至编码库,不同格式的数据放至不同的子库,不同子库之间字段可通用。后续数据探索、在线内容分析、统计分析及可视化等均基于编码库中数据进行分析。清洗数据后删除的数据放入回收库。
测试库设计用于测试编码(前测编码),要求编码员对相同的数据进行测试编码,计算编码员之间信度,在信度达到可接受的一致性水平后,开始正式人工编码。
如需要进行数据抽样,可建立抽样库,以随机或其他方式抽取部分数据,完成研究项目。
- 2. 探索:
完成数据建库后,利用网络挖掘或算法模型等机器分析方法快速分析数据,查看数据结果。平台上可查询整体数据的自动化信息量趋势和词云图。
- 3. 在线内容分析:
编码类目是内容分析法的基础,在一定程度上,类目建构的质量决定了内容分析的成败和好坏。由研究者设计编码类目,由编码员阅读文本材料并进行编码或分类。编码类目表又叫编码簿,相当于问卷调查中的调查表。
对于内容编码可使用机器编码或人工编码,对于客观性较强的类目,比如人名、机构名等,可以交由机器判断,机器编码的准确性高,速度快,效率极高。对于主观性较强的类目,比如意向态度,机器判断的准确度可能较为欠缺,建议进行人工编码。
对于质量控制,DiVoMiner®提供实时数据监测功能,可随时查看编码员工作绩效以及编码结果,提供便捷的方式修正数据结果。
- 4. 结果呈现:
完成内容分析后,可进入数据分析环节。在平台上,可快速查看单变量的频数结果(【编码结果】页面),亦支持用户自制图表(【统计分析】页面),通过简单的拖拽式操作,快速生成图表,可调整可视化效果,满足用户需求。
延伸阅读:

Leave A Comment?